Optical Character Recognition (OCR) software automates document conversion, classification, and archiving. This server-based solution transforms image-based documents into fully searchable text, streamlining enterprise search, discovery, and compliance efforts. With support for 191 languages, it handles high-volume processing while integrating seamlessly with existing document management workflows.
Designed for mid to large-scale OCR processing, this software functions as a standalone solution or an embedded component within broader document capture and management systems. Its centralized architecture allows for easy setup and universal access, reducing training requirements while ensuring consistency in document processing.
Learn more from Paperless Productivity® Founder & President, Shamel Naguib:
(Please click here to view a transcription.)
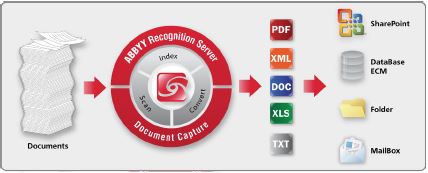
OCR software enhances SharePoint investments by improving document archiving and retrieval. The system automatically converts image-based files (TIFF, PDF, JPG, etc.) into searchable text and exports them to SharePoint for indexing. This ensures that all scanned or image-based text documents are instantly searchable and properly categorized.
Even organizations without SharePoint can leverage OCR to generate fully searchable text from scanned images. This makes the solution adaptable to any Enterprise Content Management (ECM) system, improving search, compliance, and operational efficiency.
Contact Paperless Productivity® to explore how OCR technology can modernize and transform your document management strategy.