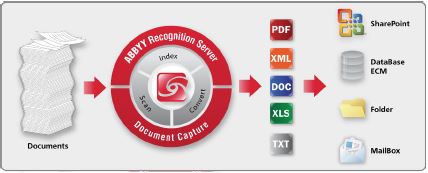
OCR, or Optical Character Recognition, software provides automated document conversion, classification and archiving. This server-based software for automatic conversion of image based documents into fully searchable content for archiving, discovery, and enterprise search. It automates OCR and document management processes with unprecedented simplicity, and can produce searchable documents between many electronic document formats in an astounding 191 languages.
Our OCR conversion software is designed for mid to high-volume OCR processing, and can be used as either a turn-key solution or a component of document capture and management structures; as either a standalone program or an integral part of a third-party system. Moreover, its server-based design allows for centralized set-up and management while retaining universal access, simplifying these processes and enabling employees to utilize its capabilities without the need for specialized training.
This is an exemplary program on both technical and business levels. As Shamel Naguib (Founder and President of Paperless Productivity®) explains below, we greatly enjoy working with this uniquely capable platform, and simply wouldn't entrust our clients' precious data to anything else.
(Please click here to view a transcription.)
Become Paperless℠ with OCR Conversion
OCR software makes document processing easy by:-
- Facilitating fast and accurate conversion of high volumes of printed documents to searchable electronic file formats—in fact, thanks to the possibility of integrating more computers and CPUs, the rate of document conversion is virtually unlimited
- Automating and streamlines routine document conversion processes in large departments and enterprises
- Integrating rapidly and inexpensively with other server-based systems and applications
- Recognizing unusual, inconsistent, or otherwise hard-to-decipher text
- Facilitating OCR for the Google Search Appliance™, enabling indexing of all scanned and photographed documents
OCR Conversion and Microsoft SharePoint
OCR conversion can effectively leverage an organization's Microsoft SharePoint investment that greatly improves document archival and retrieval processes. The server will pick up an image based document (TIFF, PDF, JPG, etc) and automatically convert the document into a fully-searchable text file for automated indexing. It then exports the text-based file to SharePoint for search and retrieval. The solution effectively maximizes your investment in SharePoint by:-
-
- Automatically delivering paper and image documents with metadata into SharePoint eliminating misplaced or misfiled documents
- Making the content of scanned or image based, text documents fully searchable
- Introducing consistency in capture, storage, and management of documents
- Archiving files digitally for easy, enterprise-wide search
-
